I worked on making sense of images,
Now I am working on images making sense.
About Me
I am Tuna ([tu-nah]), a Ph.D. student in Computer Science at Virginia Tech, advised by Dr. Pinar Yanardag Delul, and a member of the GemLab.
My research focuses on developing controllable and interpretable generative models across images, video, and language. I design alignment objectives for diffusion and autoregressive architectures to enable efficient, user-aligned generation without post-hoc tuning.
Before joining VT, I worked across startups and industry labs, building real-time image generation services and scalable ML systems in production. This mix of applied and theoretical experience enables me to create generative models that are both research-grade and deployable.
At the core of my work is a belief that generative AI should not only create high-quality content, but do so transparently and in alignment with user goals.
Current Interests
- Controllable generation in diffusion and autoregressive models
- Token-level interpretability in transformers (image/video/LLM)
- Steering of foundation models
- Zero-shot image/video editing
Recent Updates
I started Amazon AGI as an Applied Scientist Intern in San Francisco to work on Video Foundational Models
Our proposal for 'Personalization in Generative AI Workshop' at ICCV 2025 has been accepted.
Latest Blog Posts
Featured Publications

CONFORM: Contrast is All You Need For High-Fidelity Text-to-Image Diffusion Models
CVPR 2024
Images produced by text-to-image diffusion models might not always faithfully represent the semantic intent of the provided text prompt where the model might overlook or entirely fail to produce certain objects. While recent studies propose various solutions, they often require customly tailored functions for each of these problems, leading to sub-optimal results, especially for complex prompts. Our work introduces a novel perspective by tackling this challenge in a contrastive context. Our approach intuitively promotes the segregation of objects in attention maps, while also maintaining that pairs of related attributes are kept close to each other.
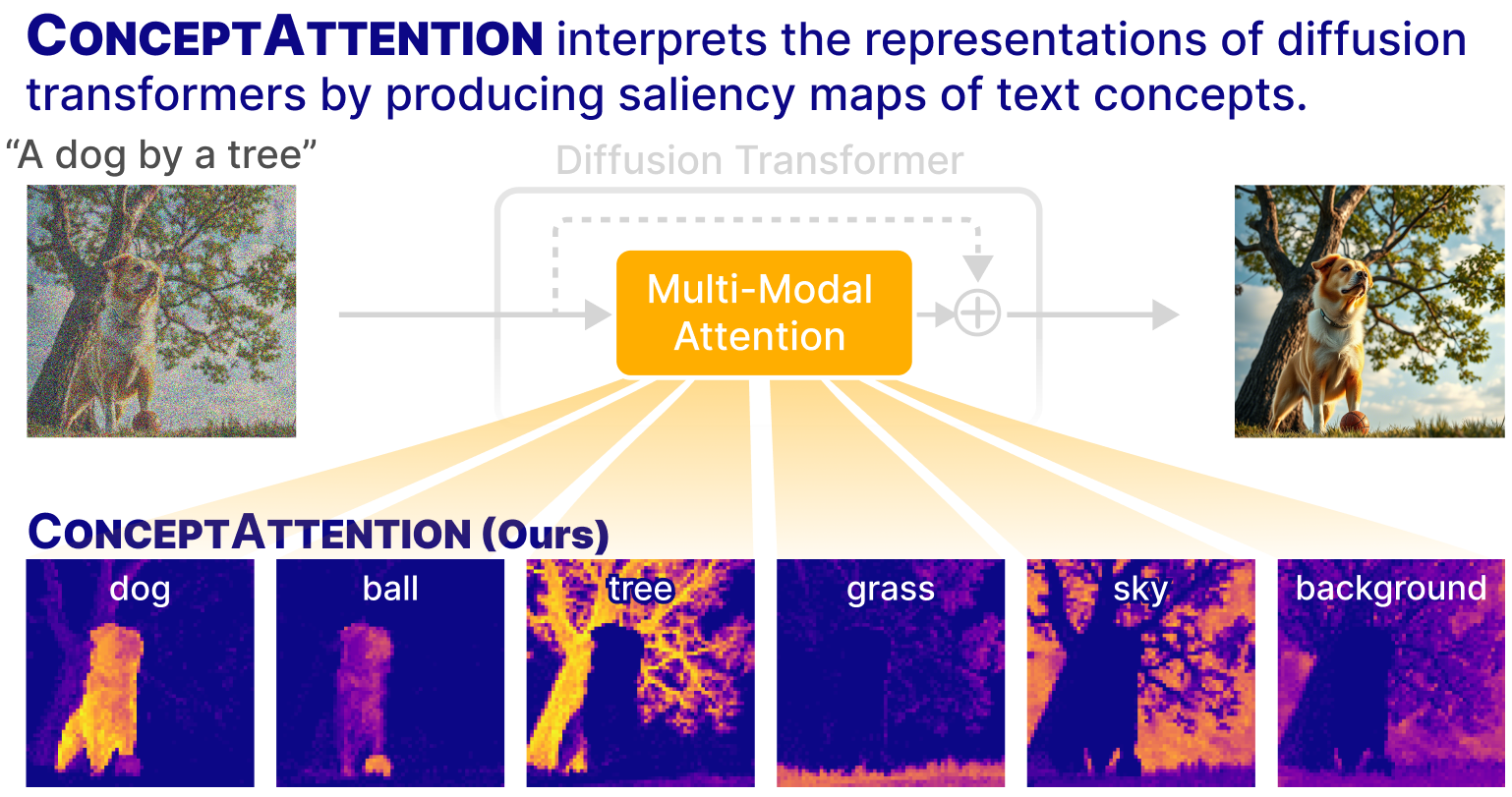
ConceptAttention: Diffusion Transformers Learn Highly Interpretable Features
ICML 2025 (Spotlight)
Without requiring additional training, ConceptAttention repurposes the parameters of DiT attention layers to produce highly contextualized concept embeddings, contributing the major discovery that performing linear projections in the output space of DiT attention layers yields significantly sharper saliency maps compared to commonly used cross-attention mechanisms.
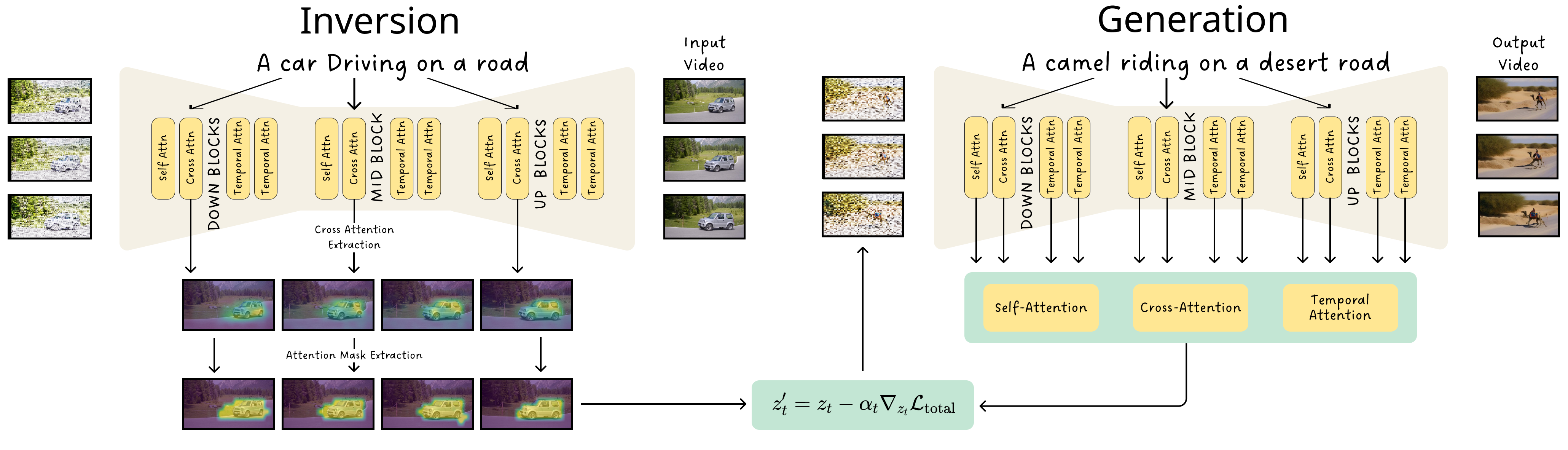
MotionFlow: Attention-Driven Motion Transfer in Video Diffusion Models
Preprint
MotionFlow is a training-free method that leverages attention for motion transfer. Our method can successfully transfer a wide variety of motion types, ranging from simple to complex motion patterns.